Analysis of beer styles main production and rating countries
Since the BeerAdvocate dataset contains ratings from users and for beers all around the world, it is interesting to investigate where each beer style is mainly produced and where it is mostly rated.
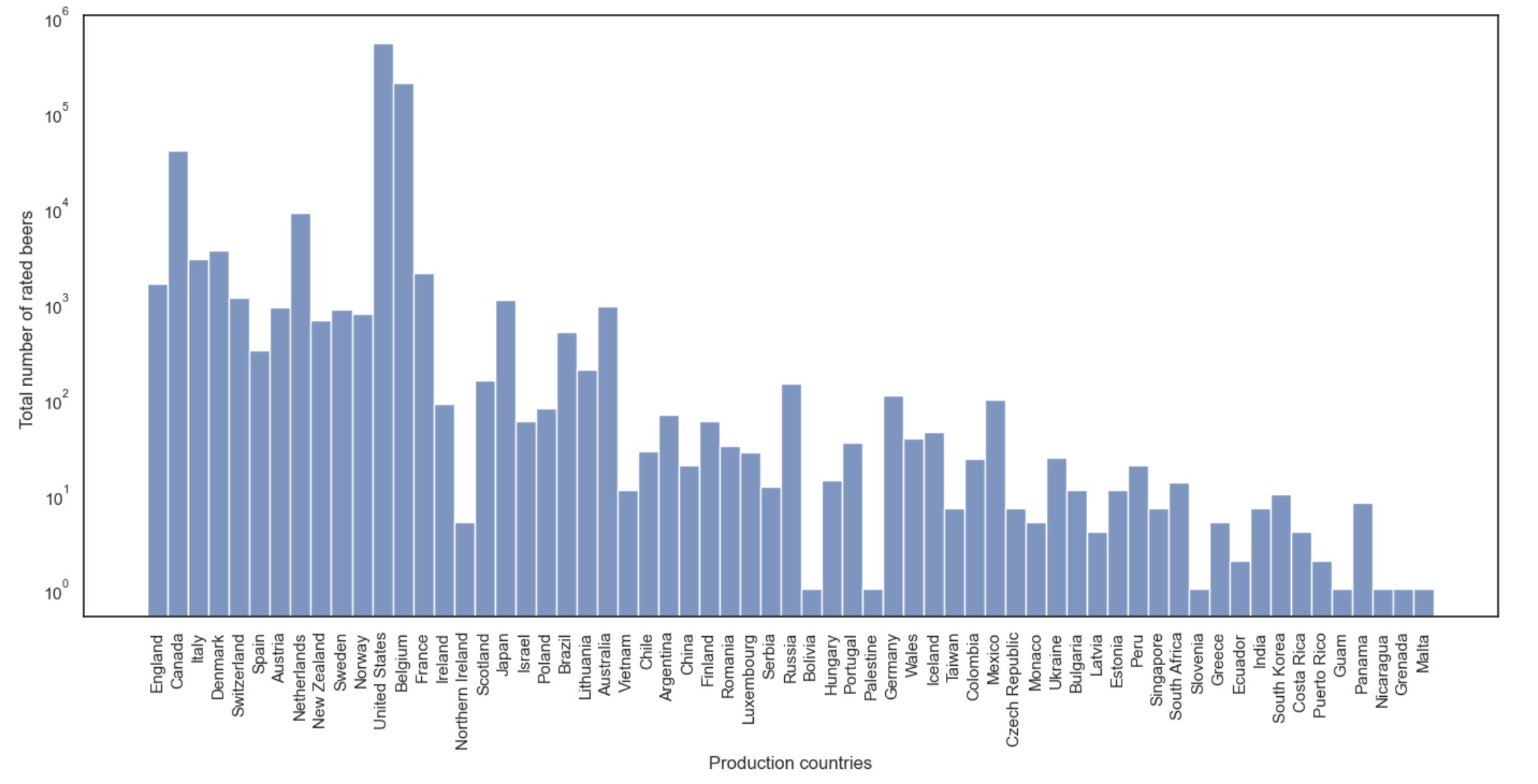
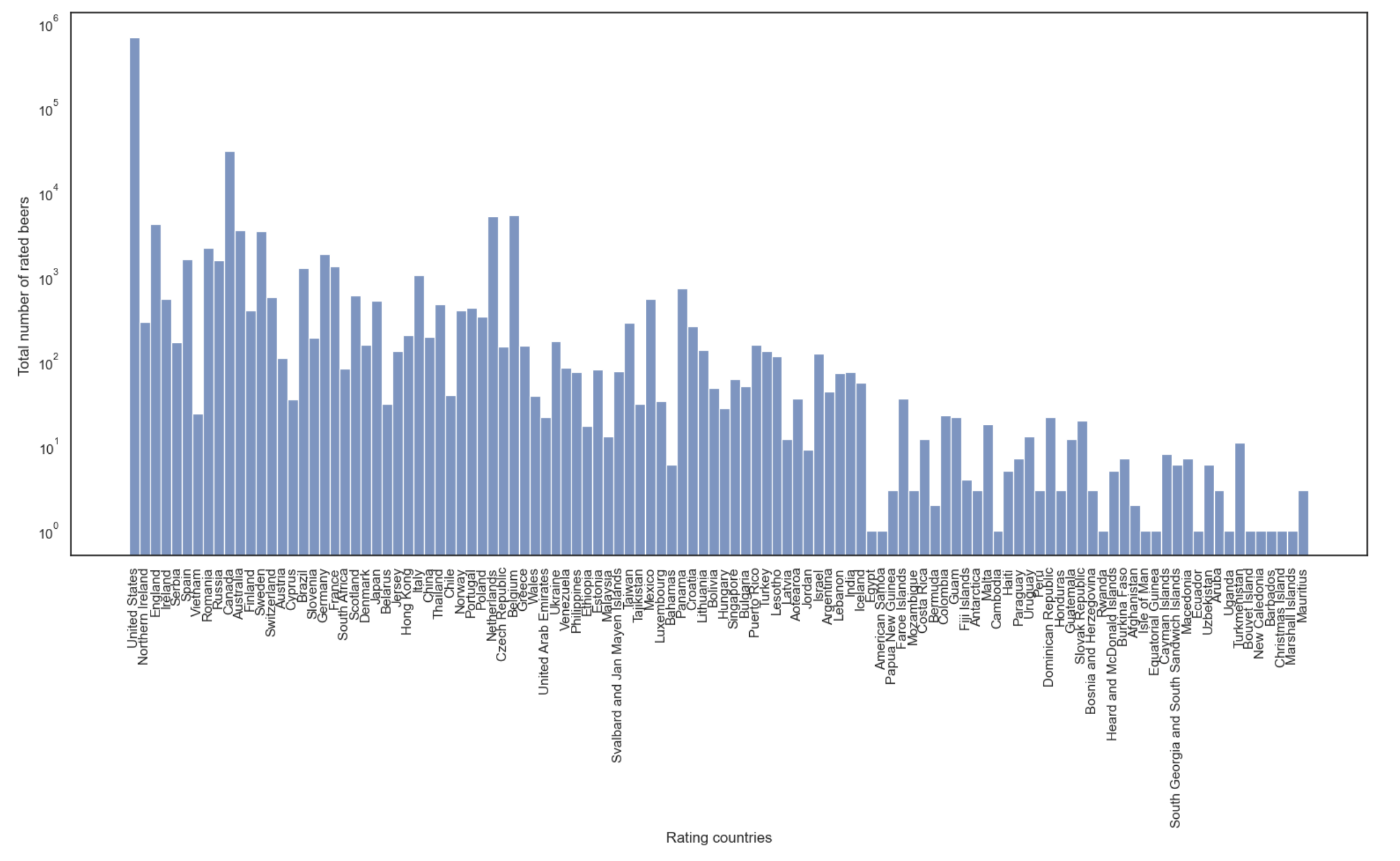
The first histogram bellow shows the distribution of production countries for the Belgian-Style ales. We observe that they are mostly produced in the United States, Belgium and Canada. The second histogram bellow shows the distribution of rating countries for the Belgian-style ales. We notice they are also mostly rated in the same three countries where they are mostly produced. This makes sense because users from a given country are likely to rate beers from their own country. We can then suppose that they will also prefer beer styles that are produced in their own country.
Analysis of supra-styles ratings
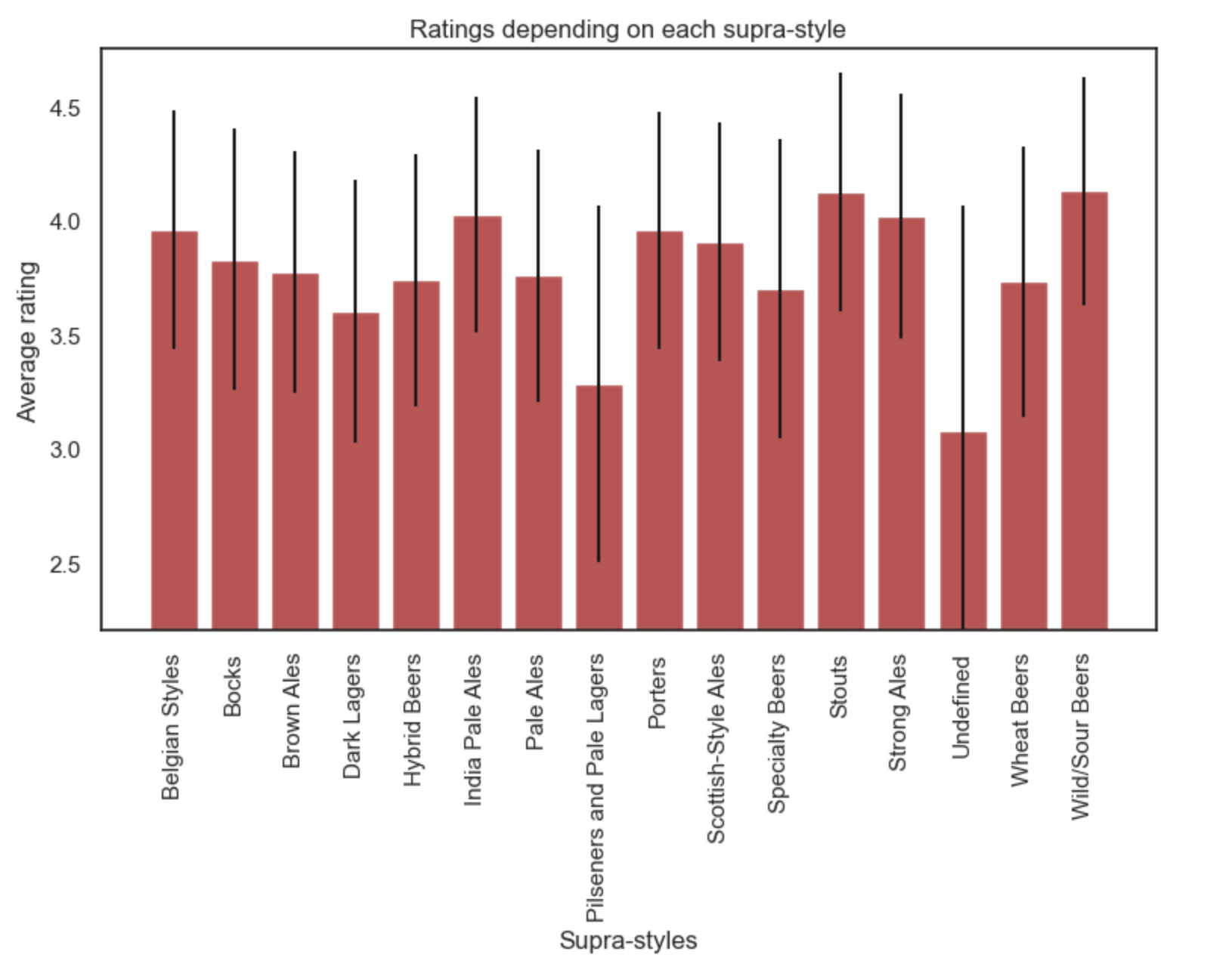
Among the 15 supra-styles, we want to observe how the ratings vary from one style to another. The figure bellow shows that most of the ratings for each style lie between 2.4 and 4.6. The mean ratings vary from one supra-style to another, the favorite style being stouts (4.1 on average) and the least favorite being Pilseners and Pale Lagers (3.4 on average).
These ratings represent the mean ratings for all the users in BeerAdvocate. However, the preferences of a user in terms of beer styles likely depend on his characteristics. We have 2 main pieces of information about a certain user at our disposal: his country of origin and his ratings. Thus, in the next chapter we will try to group the users based on these 2 features into different categories and analyze how their beer style preferences vary.
Supra styles in words
To enhance shopper experience, each beer style that successfully made it to the shelf will be briefly described textually. This will enable customers to get some information on the beer styles they might not be familiar with and guide them through their choice. The description of beer styles is generated directly from the online reviews using Natural Language Processing (NLP). It will be a list of adjectives that are recurrently employed by their peers to describe it.
To obtain this list, several steps have to be taken. Reviews have been collected from the worldwide community of beer drinkers and are hence written in different languages. Since the bulk of them is in English (99,99%), the analysis will be carried out considering only those. Reviews that have been identified as English-written with sufficient confidence are then regrouped by beer styles and stored.
Since we are interested in adjectives only for this analysis, part-of-speech tagging is being used and only tokens that have been identified as such are kept. Adjectives from reviews describing beers from the same supra style are regrouped together since the end goal of this lexical analysis is to have one description per supra style to be displayed on the shelf.
We decided to proceed with a TF-IDF approach. This term-weighting scheme relies on the (relative) frequency of terms within a document. Here a document consists of all the reviews collected for beers of one style (supra-style). The frequency of the different adjectives of the document (number of times the adjectives occur within the document) determines the weight of the document vectors. The term frequency is normalized with respect to the maximal frequency of all adjectives occurring within the document. But the caveat of such approach is that adjectives that occur very frequently in description such as “good” or “bad” and do not bring specific insight on the beer style itself will have the bigger weights. Thus, we have not only to consider how frequent an adjective occurs within a document (measure for similarity), but also how frequent this adjective is in the entire document collection made of all the reviews (measure for distinctiveness). The discriminative power of the adjective with respect to the whole document collection needs to be considered. For that purpose, the inverse document frequency is computed and included into the term weight as factor. This automatically reduces the weight for recurrent adjectives that have very little power to disambiguate beer styles.
Note that despite this idf reweighting, some irrelevant adjectives still manage to score high weights. We chose to manually filter them out and keep the 20 adjectives with highest scores for every beer style, that in theory should describe them with highest relevance. This can be illustrated with word clouds where the size of a word is proportional to its associated tf-idf weight. We show below the world cloud for the beer style Indian Pale Ales (IPA).
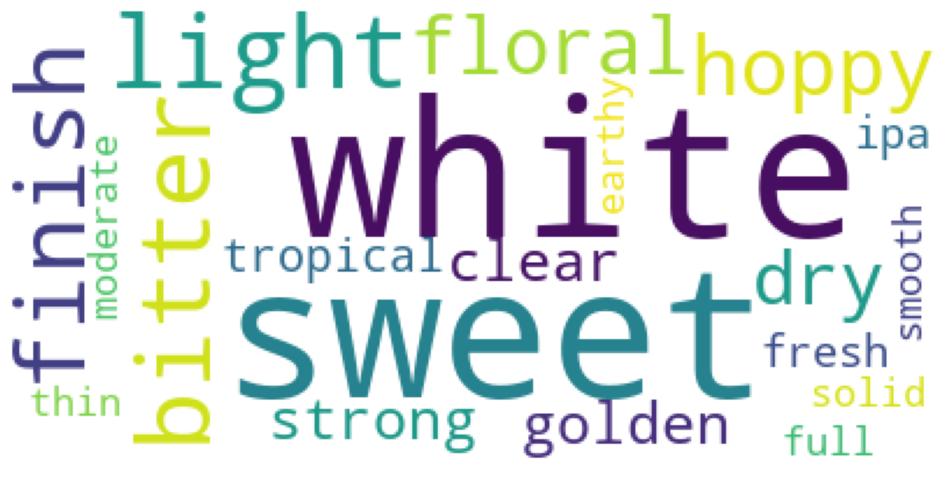
For Stouts beers, the world cloud looks like:
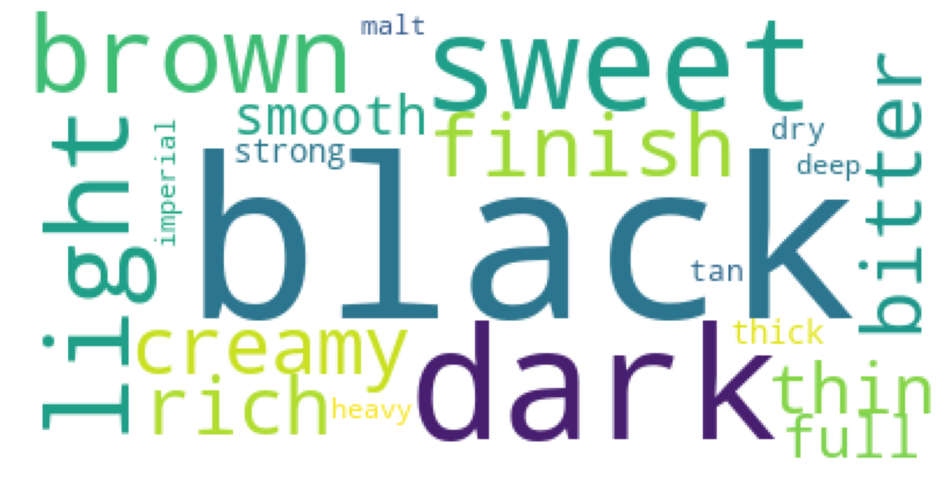
This lexical analysis was quite successful indeed as the retrieved adjectives do seem to describe quite meaningfully the beer style in question!